The convergence of ל"שרהמה and his date of death, ולסכ ב"י, in Genesis.
DRAFT. This edition: June 28, 1998. First edition: March 3, 1998.
We study the Witztum-Rips-Rosenberg (WRR) sample of nations (see [WRR2, WRR3]) and find clear evidence that their results were obtained by selective data manipulation and are therefore invalid. Our tool is the study of variations - we vary the sample of nations in many ways, and find that the variations are almost always "worse" than the original. We argue that the only way this can be possible is if the original was "tuned" in one way or another. Finally, we show that "tuning" is a sufficiently strong process that can by itself produce results similar to WRR's.
|
Dror Bar-Natan Institute of Mathematics The Hebrew University Giv'at-Ram, Jerusalem 91904 Israel. drorbn@math.huji.ac.il |
Brendan McKay Department of Computer Science Australian National University Canberra, ACT 0200 Australia. bdm@cs.anu.edu.au |
Shlomo Sternberg Department of Mathematics Harvard University Cambridge, MA 02138 USA. shlomo@abel.math.harvard.edu |
1. Introduction
1.1. Some technical notes
1.2. Acknowledgements
2. The choice of prefixes
2.1. How good is their story?
2.2. Why Vilna Gaon on Job?
2.3. "The people of X"
3. "Tuning" on War and Peace
3.1. The first story - Leaders
3.2. The second story - Celestial Guardians
3.3. The third story - Genesis ain't a War Epic
3.4. Stories, Stories, Stories
4. More evidence
4.1. The plural form
4.2. The identification of the nations
4.2.1. On orthography and on back translation
4.2.2. A bit on Targum Yonatan
4.2.3. Other identifications of the nations
4.2.4. More on Genesis, chapter 10
4.3. Other nice experiments
4.3.1. The relation to the text
4.3.2. The identifications of the nations and countries
4.3.3. An alternate form for "the language of X"
4.4. Some global choices
5. How much more have we done?
5.1. Disclaimer
6. Conclusions
6.1. A Personal note by the first author
7. Appendix: Notes on the Metric
7.1. The permutation test on control texts
7.2. Discussion
8. Bibliography
Readers who tend to shy away from mathematics are assured that they can skip everything that appears too technical and still understand practically everything that really matters.
Let us start with a very brief review of the results of Witztum, Rips, and Rosenberg. WRR argue that there is a "code" hidden in the Hebrew Bible by means of "equidistant letter sequences". That is, they argue that if one reads the Hebrew text of the Bible (or just the book of Genesis alone) in equal skips, reading only every 7th or 19th or 666th letter and ignoring all spaces, the resulting stream of letters is far from random. More specifically, they argue that often one finds within this stream a meaningful word or a meaningful phrase, and that related words and phrases found in this way tend to be found unusually close to each other. They provide anecdotal examples, but acknowledge that serious study cannot be founded on anecdotes, and thus they proceed to describe (in [WRR1]) a reasonable (though far from perfect, see section 7) statistical procedure for measuring the significance of the phenomenon.
The details of WRR's procedure appear in their paper, and are too lengthy to repeat in full in this introduction. So we give only a digest. First, they define a certain notion of "distance", c(w,w'), between a pair of Hebrew words w and w', by finding some occurrences of w and w' in the text as equidistant letter sequences (ELSs), and by measuring in some specific way the distance between such occurrences of the word w and of the word w'. Programs for computing c(w,w') are available and are not difficult to use. For example, it takes our primary computer about 30 seconds to find that c(ל"שרהמה,ולסכ ב"י)=4/125. The distances c(w,w') are by construction rational numbers between 0 and 1, with denominator at most 125. So we find that the distance between ELSs of ל"שרהמה, a designation of Rabbi Shlomo Luria, and the ELSs for his date of death, 12th of the Hebrew month of Kislev, is nearly as small as it can be. WRR argue that this phenomenon is recurring. They demonstrate it by constructing (in a certain systematic manner), a list of 32 famous rabbis, each with a list of designations, and by computing their distances to their dates of birth and death, written in several reasonable forms. The result is a list of distances (163 distances, to be precise). Some of these distances are very small (i.e., near 0) and some are very big (i.e., near 1), but overall, these distances tend to be small.
How small? Again the details are in [WRR1] and we only present a summary. WRR give this question two answers. The answer that is most relevant to us is formed by multiplying together those 163 distances and then scaling the product in a particular way to form a value between 0 and 1 called P2(names, dates) (or simply, "the P2 score") where "names" stands for the list of designations of rabbis and "dates" stands for the various dates associated with each rabbi. The result was originally intended by WRR to denote a probability, and would be quite astonishing if that were true:
The reason why this is not a probability is that the method used to compute it from the 163 distances is based on some false assumptions. In order to avoid this problem, WRR introduced a second method of giving a numerical significance value to the apparent smallness of the 163 distances. They generate one million random permutations of the list of dates, and compute P2(names,permuted dates) one million times. If P2(names, dates) turns out to be smaller than P2(names,permuted dates) in most cases, then we know that names of rabbis tend to be closer to their own birth and death dates than to the birth and death dates of other rabbis. So we don't need to interpret the smallness of P2(names, dates) directly; instead, we simply see what proportion of the random permutations are smaller than P2(names,dates). This proportion turns out to be exceedingly small - 3 of 1,000,000, to be precise. (We say that the "permutation rank" of the list of names and the list of dates is 4/1,000,000). This is a rather impressive quantitative measure of the proximity of ELSs for words with related meaning, and Witztum-Rips-Rosenberg conclude that it cannot be due to chance.
The biggest problem with this argument is that it still depends on some human input, which may have been tuned to generate the impressive final result. For example, one has to choose which designations to use for each rabbi. Maybe many "bad" designations (those that appear far from their corresponding dates) were omitted? Maybe several "good" designations were inserted artificially even though they are hardly ever used? If any of these were done, no wonder the 163 distances measured are unnaturally small as a group! In a future publication we plan to detail these problems (and a few others) in greater depth. (An intermediate partial report in [BM] demonstrates that there is enough flexibility in the definition of the data to allow an equally strong result to be "cooked up" for War and Peace.)
When one of us (Bar-Natan) confronted Prof. E. Rips with these problems, he gave several answers (to be discussed elsewhere), but also added that anyway, since the publication of [WRR1], he and his colleagues had generated several new samples that produced highly significant results and that involved no human input at all (beyond the choice of general topic). He suggested to Bar-Natan that he study these samples too. The purpose of this paper is to report our findings in relation to the "Nations Sample", the one that Rips told Bar-Natan to study first, presumably because he thought it was in some sense the best.
In brief, the Nations Sample is the following: (Full details are in [WRR2, WRR3]).
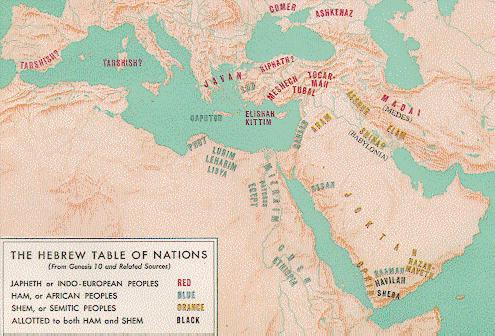
As a first list of words, take the 68 names of descendants of Noah, as they appear in [Genesis, chapter 10] (there are 70 descendants listed in that chapter, but two of the names repeat - אבש and הליוח). As a second list, of words with related meaning, take exactly the same 68 names, only with the prefixes םע (nation of), ץרא (country of), תפש (language of), and בתכ (script of) appended in front of each one (plus some additions, see below). To justify their choice, they refer to a tradition that each of the original 70 nations of the world (according to the Bible, the descendants of those 70 persons) has four attributes: its name, its country, its dialect, and its script. In addition to these four attributes, WRR sometimes associate with each nation X a few more words: the construct םיX, meaning "the people of X", and newer names for the nation of X and the country of X. These associations are made only for some nations, subject to some rules that we will review (and criticize) in section 4. The lists they get are reproduced in table 1. Within this paper, we divide their list of `related words' into two parts: the "regular part", consisting of columns 2-5 of table 1, and the "irregular part" consisting of columns 6-8 of that table.
Once again, when distances are computed between the ELS occurrences of the descendants of Noah and the `related words' in table 1, the results are astonishing. The resulting P2-score is 2.59817 10-6, and the permutation rank is even more impressive - according to our computations it is 15 out of one billion (109), according to [WRR2] it is 4 out of one billion, and according to [WRR3] it is 17 out of one billion! Again, WRR argue that this cannot be due to chance.
We note that there is some difference of methodology between [WRR1] and [WRR2, WRR3]. In [WRR1], the distance measure c(w,w') is defined by searching for occurrences of both w and w' as ELSs, and by computing (in an appropriate way) the distance between these occurrences. In [WRR2, WRR3], the distances are computed (in much of the same way) between ELS occurrences of w' (with skip greater in absolute value than 1) and straight or reverse occurrences of w (i.e., occurrences with skips +1 or -1). All the words w that are considered in [WRR2, WRR3] are names of descendants of Noah, and by the nature of their definition, they all appear in [Genesis, chapter 10] with skip +1. This difference of methodology explains the "Relation to the Text" in the title of [WRR2] - what [WRR2] seem to prove is that there is a relationship between the "coded" occurrences of the words w' in columns 2-8 of table 1 and the "straight" occurrences of the words w in the first column of that table. For a technical reason, WRR restrict the definition of c(w,w') to words w' that have between 5 and 8 letters. No such restriction is imposed on the word w.
In this paper we criticize those impressive results of Witztum, Rips, and Rosenberg, and show them to be invalid. We show that there is much more choice in making up table 1 than meets the eye; enough choice to generate a similar result in several control tests. More importantly, we show that whenever WRR had to choose, they somehow knew to make the choice `correctly' - namely, to make the choice that makes their result appear more significant. We find this difficult to accept if the data was correctly prepared without peeking at it first. In section 2 below we present a strong piece of evidence that such `tuning' was done: we measure the P2 score of the same list of 68 names with 136 other lists, obtained by adding 136 different reasonable prefixes to these names. We get 136 scores (that seem to be pretty random, as a whole), and it turns out that 3 of the 4 prefixes that WRR use, םע, בתכ and תפש, are the top 3 scorers in our list of 136! This is a rather improbable result; we believe it suggests that Witztum, Rips, and Rosenberg cheated and tried (either directly or indirectly, see section 2) many possible prefixes before deciding which four to use. They've added the fourth prefix, ץרא, only because they needed to build a reasonable story around the other three.
Could it be that WRR first had the story and only then chose the prefixes? Even if so, the fact that there are many other very good possible prefixes whose P2 success is rather low, means that in this context there is no unusual proximity of ELSs for nations and related notions. But anyway, we explain that this possibility is rather unlikely. The question boils down to "how many as-good stories are there?". If there are many, how come they've picked just the right one? And so we spend the rest of section 2 criticizing their story. The following section, section 3, shows that there are very many good stories indeed. In fact, so many that we could choose one that got a permutation rank of 5/108 on a control text! (The regular part of their sample, involving only the four prefixes, gets a permutation rank of only 566/108).
In section 4 we present some more evidence that WRR tuned their data to get the results they wanted. In section 4.1 and section 4.2 we consider a few variations of the irregular part of their sample. In all cases we find that the variations we considered are `worse' than the original, suggesting that the original was somehow optimized. In section 4.3 we report on a few experiments that by the WRR logic should have been successful, but aren't. In section 4.4 we report on some global choices WRR had in arranging their list. There we find some variations of the WRR experiment that improve its results slightly, but it seems that testing these variations was almost impossible given the technical means that were available to WRR.
Following a brief disclaimer in section 5, we discuss our results and present our conclusions in section 6.
els2.c.
We modified it to work under Unix and re-wrote the permutation test
part, but made no modifications to the main part of the code. The text
of Genesis and the text of War and Peace we used were also given to us by
WRR, though we've modified the text of War and Peace to get the text
WGP, as described in section 3.
We also wish to thank Maya Bar-Hillel, Alec Gindis, Gil Kalai, Michael Sokoloff, and the others who helped, for their suggestions and support.
Let X be a name of a nation, as in [Genesis, chapter 10]. The WRR results are that ELSs for X tend to appear in close proximity to ELSs for Xםע, Xץרא, Xתפש, and Xבתכ. If this is so, it is unnatural to believe that this phenomenon is restricted to these four prefixes. We would expect that X would also appear in close proximity to Xינב, to Xךלמ, to Xיבא, and to X itself, without any prefix. With that in mind, we made a list of some 129 possible prefixes, and tested them all. Only prefixes in the length range 2-4 were considered. Longer prefixes produce very few distances, as attaching them to a nation name nearly always gives a word longer than 8 letters or a word with no ELS. Later on we tried a few additional prefixes, and we decided that it is better to disregard a few prefixes whose original inclusion was based on an error (misspelling, irrelevance). We were left with some 136 reasonable prefixes, shown in table 2. (The prefixes we decided to disregard are shown in table 3, to allay any suspicion that we were selective in our choice of prefixes.) We then computed the P2 score corresponding to each one of the table 2 prefixes. The results of this computation are shown in table 4. The prefixes in that table are ordered by increasing P2 score. Some have a very good P2 score, some have a bad P2 score. Overall, it seems that the P2 scores observed are distributed rather evenly in the relevant range (between 0 and 1), and the corresponding permutation ranks (also shown in table 4) exhibit behavior not unlike what one would expect (see section 7 for a detailed analysis).
This by itself is a significant piece of evidence against the work of WRR. Essentially, we have just performed 132 attempted reproductions of the WRR experiment (4 of our 136 prefixes are the 4 used by WRR). If there were any truth in the phenomenon of codes, we'd expect to see many "good" P2 scores and permutation ranks (values near 0), and only a few bad ones (values near 1). This is not what we get, and hence we view our 132 attempted reproductions of the WRR experiment as 132 failures.
But this is not all. Take a closer look at table 4; the biggest question mark regarding WRR's work is right there. If they did not have some prior knowledge, how does it happen that three of their four prefixes are the top three successes in table 4?
It is pointless to compute the odds of that happening by chance alone; some prefixes are clearly "better" than others. If codes do exist in the book of Genesis, they are probably more likely to speak of רמג םע (the nation of רמג) than of רמג ריש (the song of רמג). But why don't the codes speak about obvious and often-used constructs such as רמג ינב, (people of רמג) רמג ךלמ (king of רמג), רמג לא (God of רמג) or רמג אבצ (army of רמג)? Can one seriously say that רמג בתכ (script of רמג) is more likely to be coded than רמג לגד (flag of רמג), רמג ערז (seed of רמג, offspring of רמג) or רמג יאטח (sins of רמג)? And who would have guessed that the Vilna Gaon would himself suggest the prefixes סומנ (laws of, manners of) and שובל (dress of, clothing of), that a-priori seem somewhat artificial? (See section 2.2). While we cannot put a number on it, it is clear that the chance of picking the top three prefixes from within so many possibilities without any prior knowledge is very small.
(Just to get a feel for the scale: if there are just 50 prefixes and they are all equally likely, the probability of choosing four at random and finding that three of them are the top three is 1 in 4,900. If there are 100 such prefixes, the probability drops to 1 in 40,425.)
So maybe some prior knowledge was available to the authors of [WRR2, WRR3]? We can't tell exactly how they gathered such knowledge. Maybe they stared at rectangular-shaped printouts of the book of Genesis for a very long time, until they found a few anecdotal appearances of רמג םע or גוגמ תפש, and only then they decided to turn it into a full scale sample? Maybe they found ELSs for, say, דשכפרא, continued them backward and found that they tend to be preceded by בתכ, and only then they've decided to use the prefix בתכ in their sample? Maybe they simply made up a table like our table 4, decided to use םע, בתכ, and תפש, and then cooked up a good story around these prefixes and added the prefix ץרא to make the story look better?
This brings us to the question, how good is the story? True, we have 132 failed replications and thus at least as many question marks, but maybe the wonder isn't with the non-existent success of the many prefixes in table 4, but rather in the nice story woven around the top prefixes in that table? After all, maybe the mere fact that such a nice story can be sewn around the top successes is by itself a miracle? The experiment is not a quantitative proof of that, and putting probabilities next to it (as WRR attempt to do) is silly, but still, isn't it impressive enough? So our next task is to try and see how good the story really is, and how hard it is to make up stories just as good.
Jewish tradition further tells us ([VG1]), that a nation has the following four characteristics:
- its name.
- its country.
- its language.
- its script.
Let us take a closer look at the relevant section in [VG1], a commentary on the book of Job by the Vilna Gaon:
In plain English (our translation),
It is known that nations in the holy scriptures are distinguished by four characteristics: 1) by their name. For each nation is called after their first father from whom they descend, viz. Cush Mitzraim (Egypt), Phut, Canaan, etc., so that until the present day they are called Egyptians, Edomites, all on account of the originator. 2) By the name of their country. For the names of the countries are also called after the founders, like the land of Egypt - it is named after its founder. Similarly the land of Cush, the land of Canaan and so on. 3) By dialect. For each nation agreed upon a special dialect which is called the Egyptian dialect, the dialect of Cush. 4) In script. As each nation has its own script. These four characteristics you can find explicitly in Genesis chapter 10: "These are the sons of Shem according to their families, their dialect, in their lands, according to their nationalities." The phrase "their families" is the first distinction - that the nation as a whole is named after the head of the family from which it was hewed. "Their dialect" is the third distinction - that they all differ with distinct dialect for each. "In their lands" refers to the second distinction - and turns on the names of their countries. The fourth distinction - in the script - is also hinted at in the passage "their families , their nations" - that each and every people is called a "nation" unto itself without lacking anything.
Let us see what choice of prefixes would seem to follow if we accept the Vilna Gaon's defining characteristics of nationhood. The third characteristic is dialect - ןושל is the word that the Vilna Gaon uses to describe dialect, and it is the word that the Torah uses. But instead, WRR use the word תפש. Notice that that the prefix תפש is very successful for their purposes (see table 4). Indeed, the words הפש and ןושל are not completely synonymous. According to the commentary of Rabbi S. R. Hirsch [Hi] to this passage, הפש should be translated as "language" while ןושל means "dialect".
Now let us turn to the first criterion - description by "name". The most reasonable constructions suggested by the Vilna Gaon's explanation would be to apply the prefix םש (name of), or to use the plain name of each nation without any prefix. Both possibilities give poor results. Instead, WRR chose to use the prefix םע, which only makes sense if it refers to the actual forefather - the nation of Gomer, for example. But WRR use it even as a prefix to the plural forms - the nation of the Ludites, in which case it has nothing to do with the Vilna Gaon's first criterion. Furthermore, the Torah uses the word יוג for nation, not םע. The Vilna Gaon in a commentary related to this chapter [VG2, on Isaiah 1:4] makes a point of explaining the distinction in meaning between these two terms. The prefix יוג performs much worse than םע, so again it seems that the choice made by WRR to use םע was to optimize their outcome, not as a result of any objective criterion.
There is a bit of additional "story" in [WRR2]. They say they choose the prefixes םע, ץרא, and תפש because they appear as prefixes in "Biblical expressions", and that using בתכ as a prefix would make a "Biblical formation" where a "Biblical expression" does not exist. This very much seems like an ad-hoc excuse, and different and as good ad-hoc excuses could have been invented to support the prefix ןושל (used by the Vilna Gaon in the above quote derived from [Genesis, chapter 10]), the empty prefix, or, for that matter, almost any other prefix. Furthermore, it is hard to take seriously the "Biblical expression" excuse, that applies to only 3 of the 4 prefixes and that applies just as well to many other prefixes that fail miserably. We also note that the issue whether a word is Biblical or not didn't seem to matter when WRR assembled columns 7 and 8 of table 1, where even misspelled non-Hebrew words are used.
In summary, the prefixes chosen by WRR are but poorly supported by the story they bring in support of them. Prefixes more obviously suggested by their story do much worse.
In short, the Vilna Gaon says that after the Deluge the people split into 70 nations, and lists four reasons: different families (the prefix תחפשמ, "family of"), different dialects (the prefix ןושל), different countries (the prefix ץרא), and different laws (the prefix סומנ). Running the permutation rank program on Genesis with these four prefixes, the rank we get is 6/100, about 10,000 times worse than the rank the four WRR prefixes get, even though we share one prefix with them. Using the alternative spelling סומינ instead of סומנ the score is 9/100 - even worse. Using גהנמ instead of סומנ we do a bit better and get a score of 3/100 (still 5,000 times worse than WRR), but we cannot justify this replacement either by reading the Vilna Gaon quote shown above or by reading the Bible, where the meaning of גהנמ is "driving" or "charioteering", and not "laws" or "manners". Were WRR just lucky to choose the Job commentary over the Isaiah commentary?
In yet another place, his commentary on the book of Esther [VG3], the Vilna Gaon writes
.. because the nations differ by 4 attributes, by script בתכ and dialect ןושל, and country ץרא - ..., and by dress שובלמ.
Here we are led to consider the four prefixes בתכ, ןושל, ץרא, and שובלמ (or שובל). With two prefixes in common with WRR, the permutation rank here is a mere 8/1000. Replacing שובלמ by the shorter and equivalent שובל, we get 89/1000. Replacing it by the common דגב, we get 31/1000. Were WRR just lucky to choose the Job commentary over the Esther commentary?
Another possibility is to read one of the verses on which the Vilna Gaon bases his commentaries, [Genesis 10-5]:
By these were the isles of the Gentiles divided in their lands; every one after his tongue, after their families, in their nations.The prefixes suggested here are יא (isle of), ץרא (country of), ןשל (tongue of, meaning dialect of), תחפשמ (family of), and יוג (nation of). The permutation rank is 130/1000, another failure.
But the secret of the matter is in the verse which states "When the Most High gave to the nations their inheritance, when He separated the children of men, He set the borders of the People" etc. "For the portion of the Eternal is His people" etc. [Deuteronomy 32:8-9]. The meaning thereof is as follows: "The Glorious Name" [ibid. 28:58] created everything and He placed the power of the lower creatures in the higher beings, giving over each and every nation, "in their lands, after their nations" [Genesis, 10:31] some known star or constellation, as is known by means of astrological speculation. It is with reference to this that it is said. "which the Eternal thy G-d hath allotted unto all the people", [Deuteronomy 4:19] for He allotted to all nations constellations in the heavens, and higher above them are the angels of the Supreme One whom he placed as Lords (םירש) over them, as it is written, "But the prince (רש) of the kingdom of Persia withstood me" [Daniel 10:13] and it is written there, "lo the prince (רש) of Greece shall come" [ibid, 20]. They are called "kings" (םיכלמ) as it is written [there] "and I was left over there beside the kings (יכלמ) of Persia" [Daniel 10:13]. Now "the Glorious Name" [Deuteronomy 28:58] is "G-d of gods (םיהלא), and Lord of lords" [Deuteronomy 10:17] over the whole world. But the Land of Israel, which is in the middle of the inhabited earth, is the inheritance of the Eternal, designated to His name. ...... nations over whom He appointed princes (םירש) and other celestial powers (םיהלא), ...
... since He is the G-d of gods Who rules over all, and He will in the end "punish the host of the high heaven on high", [Isaiah 24:21] removing the celestial powers and demolishing the array of the "servants", and afterwards He will punish "the kings of the earth upon the earth" [Ibid.]. This is the meaning of the verse stating "The matter is by the decree of `irin' (ןיריע) (the wakeful ones) and `sh'elta' (the sentence) by word of the holy ones" [Daniel 4:14], meaning, the matter that was decreed on Nebuchadnezzar [that he be driven from men and he eat grass as oxen etc.] is the pronouncement of the guarding angels and the sentence of the word of the holy ones, who have ordained on the powers emanating from them that it be so. They [the angels] are called irin (ןיריע) [literally: "the wakeful ones"] because from their emanations proceed all the powers that stir all activities, similar to that which it says, "and behold `ir' (ריע) (a wakeful one) and a holy one came down from heaven. He cried aloud and said thus: Hew down this tree" etc. [Daniel 4:10-11]. ...
... This is the meaning of the expression, "and he will go astray after the foreign gods (יהלא) of the land", ...
Notice that he uses the phrase ךאלמ (angel) as the supervisor or רש of the constellation of each nation. In this connection he uses the phrase ןוי רש, for example, to illustrate his principle. He maintains that these supervisory angels can also be referred to by the prefix יכלמ and also illustrates it by referring to סרפ יכלמ. He also refers to these guardian angels as םיהלא and as ןיריע. For this reason, we may feel fully justified in choosing as our prefixes יכלמ, רש, ריע, and יהלא. Notice that these four words all appear explicitly (three of them as prefixes) in the above quotation. When a word appears in the quotation in both singular and plural form, we always prefer the (shorter) singular form. When it appears only in plural form, we can't know if it is reasonable to use it in singular form and hence we keep it in plural form.
Running our program again, using these four prefixes on the text WGP, we get a permutation rank of 5/108, about 100 times better than the WRR prefixes on Genesis! Once again our prefixes get a boring result on Genesis (310,817/106), so our result is not due to the G piece in WGP.
Consider the prefixes ליח (army of, corps of), דודג (battalion of), ברח (sword of), and יפלא (thousands of, family of, part of the tribe of). The first three are clearly war-related. The fourth also feels war-like to the Hebrew-trained ear. That feel is confirmed by the verse
It is quite un-surprising that such a war-like lineup of prefixes does well on the war-epic-based WGP, getting a permutation score of 6/1000. It is just as expected that on Genesis, a book of creation and holiness, this lineup fails miserably, getting a permutation score of 999,460/1,000,000.
Of course, the real question is not how many successful stories can be found for Genesis or WGP. The real question is: faced with a set of prefix performances which are essentially random, what is the probability that a successful story can be woven around some of the best prefixes? It is a very difficult question, but our success with WGP and the experience it gave us suggests that the probability is quite good. The number of potential stories is so vast that one of them is almost certain to be a winner.
Obviously we could also use our data to concoct additional stories that give good results for Genesis. Readers should remember that our case is that finding good stories is easy for any text.
Concerning the expressions "םיX" [meaning: the people of X], we are aware of the fact that only valid linguistic formations should be used; therefore we use these expressions if, at least, their singular form יX appears in the Hebrew Bible. For instance, for רמג (item 1) we do not take םירמג, since the expression ירמג does not appear in the Hebrew Bible; so we cannot know whether it has any meaning at all. The check was done using Even-Shoshan's New Concordance of the Bible (Even-Shoshan, 1981).
The decisions WRR made in this paragraph seem completely arbitrary. Why not take all plural forms? In most cases no Hebrew speaker would have any difficulty deciding what the correct plural gentilic form of a given nation's name is, even if no hints are given in the Bible. Alternatively, why not require that the plural appears explicitly in the Bible? And why remove the definite article from nations 36-44 (from יסוביה through יתמחה)? This they did without even telling us about it even though they kept it except in this place. In addition, it seems that WRR did not even fully comply with the rule they stated above, for they have taken םירושא as the plural form of רושא. The word םירושא does not appear in the Bible, and the word ירושא appears there once, in reference to the tribe of רשא. When the people of רושא are mentioned in the Bible, they are called םרושא. Finally, there is a problem with the treatment of םידול. See below.
It turns out that if WRR's mistake is corrected or if any of their decisions is reversed, it always weakens their result. Is it reasonable to assume that WRR knew which column to choose if they didn't try some of the other possibilities? Here are the relevant scores in a tabular form: (the raw data is in table 6)
| WRR | WRR without םירושא | WRR with םרושא | WRR without םידול | Common Sense Extension | Explicit Plural | In Chapter | Keep ה | All With ה | |
| Number of words considered | 33 | 32 | 33 | 32 | 62 | 23 | 19 | 33 | 33 |
| Score | 4,836 | 28,534 | 44,661 | 14,683 | 119,448 | 70,361 | 133,070 | 18,745 | 609,227 |
Let us explain the columns of this table.
In Talmudic literature we find various new names for nations and countries, and we cannot decide in favor of one against the other. We preferred to use a single source. The Aramaic translation of Genesis that gives the largest number of new names is Targum Yonatan. We used Targum Yonatan as printed in Torah Shelemah (Kasher, 1929) (with Torah Shelemah's corrections according to the Ginsburger manuscript and others). ...In this section we wish to study how reasonable was WRR's choice of a source, how faithfully they followed it, and whether the idea of looking for the "new" identifications of the nations and the countries was sound to start with.... Targum Yonatan is a translation into Aramaic. We need the identifications of the nations, but we do not intend to check whether the Aramaic appears non-randomly as ELS's. Thus, where the Hebrew formation exists, we used it alone.
... Here, as in [WRR1], we used the grammatical orthography - ktiv dikduki.
As it turns out, undoing any of the first 5 of the WRR corrections weakens their result (and the last 2 are irrelevant, as noted above):
| WRR (columns 7 and 8 of table 1) | turning ידמה back to יידמה |
turning אינודקמ back to אינידקמ |
turning איכא back to אייכא |
turning ברע back to איברע |
turning בול back to יאבול |
| 4,277 | 11,891 | 11,872 | 5,737 | 5,599 | 9,105 |
It is interesting to note that the job of back-translating Targum Yonatan into Hebrew was carried out earlier, for completely different purposes, by Rieder [Ri2]. We have extracted the Hebrew formations out of [Ri2], and kept the Aramaic where [Ri2] gave no parallel Hebrew formations, getting a new list of identifications. This list (which has a better claim to be "correct" than the WRR list, as it was made in advance by an independent professional) is shown in the column titled "WRR with Rieder's Hebrew (literal)" in table 9. The column titled "WRR with Rieder's Hebrew (modified)" is the same, only that we've attempted to convert Rieder's original spellings into what appears to be the WRR notion of correct spelling - namely, we've reduced double Yuds into single Yuds and used the word both with and without the vowel "א" when it appears as a "mater lectionis" (see [WRR1]). The column titled "WRR - Modified Ginsburger" contains the original WRR choices. The results of the permutation test for these lists of identifications are shown in table 10. The two "Rieder's Hebrew" lists get results which are about 100 times weaker than the WRR result!
Note. WRR often prefer to spell geographical names with a final א, rather than with a final ה. When the final ה's in the two "Rieder's Hebrew" columns are replaced by א's uniformly (except for האירברב, which ends with a ה even in the "WRR" column), the permutation test scores are slightly better but they are still statistically insignificant and around 50 times worse then the WRR score. For the "literal" column the score is 157,726, and for the "modified" column it is 230,659.
| WRR - Modified Ginsburger | WRR with Rieder's Hebrew (literal) | WRR with Rieder's Hebrew (modified) | WRR, reducing וו | WRR with םי | WRR with יא | WRR with ה |
| 4,277 | 401,722 | 462,379 | 10,036 | 4,752 | 9,036 | 9,325 |
The other columns in table 9 and table 10 are:
After this section was completed, Doron Witztum issued a paper [Wi] in which he gave the following clarification of his 'ktiv dikduki' rule:
The original quote reads, "For words in Hebrew, we always choose what is called the grammatical orthography ...". Note that we specifically say "words in Hebrew," not "Hebrew words" - that is, any word which has been rendered into Hebrew, even if derived from a foreign language, is to be written in grammatical orthography. The only expressions which do not fall under this rubric are words derived from languages which themselves use Hebrew characters, such as Yiddish and Ladino, because these languages do not need to be rendered into Hebrew. This rule was followed consistently in the construction of both published lists regarding all foreign names.We sincerely wonder if Mr Witztum really believes what he wrote, as both the English phrase "words in Hebrew", and the Hebrew phrase "תירבעב םילמ" (which is how the rule appears in [WRR3]) mean "words belonging to the Hebrew language", which does not include foreign words merely transliterated into the Hebrew script. Nevertheless, our present interest in the quotation concerns the reason given for excluding Yiddish and Ladino. It is obvious that Aramaic fits the same conditions perfectly. Therefore, according to Mr Witztum's own interpretation, whether or not it makes sense, we should not apply 'ktiv dikduki' to Aramaic words, nor in fact modify their spelling in any way. Obviously this contradicts what he did in [WRR2].
In any case, the primary issue is not whether it is defensible to apply 'ktiv dikduki' to Aramaic words. The primary issue is whether it was required of WRR to do that. The answer is clearly that they had a choice, as they had not considered Aramaic words before (to our knowledge) and their rule can be argued to apply or not very easily. As we have demonstrated, they made the decision in the way most favorable to themselves and then applied it in the most favourable way, even to the extent of making advantageous errors.
The first of these manuscripts cited by de Rossi is thought to have been the basis of the first printing in Venice (1591) where the false title Targum Yonatan ben Uziel is used. The second manuscript - the only known one to still exist - is in the British Museum and was published by Ginsburger in 1903. This formed the basis for Rabbi Kasher's editorial notes in his Torah Shelemah. Unfortunately, Ginsburger's work was unreliable, so the whole basis of the choices of WRR is without foundation. More on this later.
The so-called Targum Yonatan ben Uziel is more than a mere translation. It includes much Aggadic material collected from various sources as late as the Midrash Rabbah as well as earlier material from the Talmud. So it is a combination of a commentary and a translation. In the portions where it is pure translation, it often agrees with the Targum Onqelos.
As to the date of its composition, this is a matter of dispute. The majority opinion, on the basis of much internal evidence, is that it cannot date from before the Arab conquest of the Middle East despite incorporating some older material. For example, Ishmael's wife is called by the legendary Arabic name Fatimah. Such evidence is summarised in [Ma]. As an upper bound, it is referred to (perhaps for the first time) in 15th century commentaries. Gottleib [Go] puts the time of composition toward the end of the eighth century. On the other hand, since the Geonim are unfamiliar with it, and Rashi doesn't mention it, Rieder [Ri1] puts the composition some time after Rashi, perhaps during the period of the crusades. The one surviving manuscript was probably written in the 16th century and is an unknown number of generations removed from the original.
Now to Ginsburger's "corrections" which were incorporated by Rabbi Kasher into his Torah Shelemah. Rieder (Leshoneinu vol 32. p.298) demonstrates that Ginsburger's edition is full of errors and incorrect copying and that it confused the printed version with manuscript and vice versa. Rieder writes as follows in the introduction to his edition [Ri1]:
The many errors in the edition of Ginsburger have tripped up many investigators in their work. Outstanding among these is Rabbi M. M. Kasher, in his Torah Shelemah where he copied the errors of Ginsburger or his "corrections" as if they were actually in the manuscript.He goes on to give many startling examples of such false "variants".
The third author would like to record here his fond memory of many pleasant and instructive conversations he had with Rabbi Kasher over 40 years ago. Rabbi Kasher was a man of great warmth, intelligence, and wit. In a work of such encyclopedic proportions as the Torah Shelemah, it was inevitable that he had to rely on the scholarship of others, rather than to examine all manuscripts himself. It is unfortunate that he was tripped up by Ginsburger.
To remedy the poor choice of the Ginsburger "corrections" made by WRR, we have also run the permutation program using the Rieder edition of the Targum Yonatan, and using the Targum Yonatan manuscript printed in [Cl]. The identifications of countries and nations in the Rieder edition of Targum Yonatan and in [Cl] are presented in the columns labeled "Rieder" and "Clarke", respectively, in table 11 (note that we've treated the יא suffixes in the same way as WRR). The columns labeled "Modified Rieder" and "Modified Clarke" in table 11 are the same, only that we've tried to back translate Rieder and [Cl] to Hebrew and use "grammatical orthography" following the precedents in [WRR2, WRR3]. The column labeled "Ginsburger" in table 11 contains the source of the Ginsburger "corrections" as it appears in [Ka], and the column labeled "Modified Ginsburger" is the same, only modified as in [WRR2, WRR3] - in other words, it is simply the WRR choice of identifications.
We have also run the permutation program on several other plausible lists of identifications (well, at least no less plausible then WRR's choice). These lists are also printed in table 11, under the columns labeled "Targum Yerushalmi" and "Modified Targum Yerushalmi" (Targum Yerushalmi as printed in [Ka]), "Talmud Yerushalmi" and "Modified Talmud Yerushalmi" (Talmud Yerushalmi as in the Responsa database [Re]), "Talmud Bavli" and "Modified Talmud Bavli" (Talmud Bavli as in [Re]), and "Midrash Rabbah" and "Modified Midrash Rabbah" (Midrash Rabbah as in [Re], Vilnius version).
The results of these runs of the permutation program are printed in table 12. The rows labeled "#" in that table contain the number of identifications appearing in each source.
| Source: | Ginsburger | Rieder | Clarke | Targum Yerushalmi | Talmud Yerushalmi | Talmud Bavli | Midrash Rabbah |
| # | 39 | 39 | 34 | 22 | 16 | 10 | 22 |
| Score: | 66,445 | 721,658 | 686,283 | 54,081 | 870,221 | 453,783 | 482,268 |
| Source: | WRR - Modified Ginsburger | Modified Rieder | Modified Clarke | Modified Targum Yerushalmi | Modified Talmud Yerushalmi | Modified Talmud Bavli | Modified Midrash Rabbah |
| # | 38 | 37 | 32 | 22 | 16 | 10 | 22 |
| Score: | 4,277 | 353,231 | 285,627 | 180,365 | 104,791 | 85,065 | 563,935 |
This table clearly indicates that the decision WRR made (to use Ginsburger's Targum Yonatan) worked to their benefit.
One other thing that we tried was to collect
Oddly enough, the opposite turns out to be true, as shown in
table 13, with the
corresponding raw data in table 14. In table 14, the column titled "Kasher"
contains the identifications appearing in Kasher in their literal form
(except that we've treated the יא suffixes like WRR do), the column
titled "Modified Kasher" is the same only that we've used the WRR
precedents for back translation and grammatical orthography, and in the
column titled "Modified Kasher, reducing וו" we've further reduced
all occurrences of וו to ו, as explained in
section 4.2.1.
We note that the Kasher data fully contains the Ginsburger data (by
definition: the Ginsburger data appears in the Kasher book), and
hence any optimization that WRR may have performed on the Ginsburger data
(the choice of spelling rules and of back translation, the mere fact it was
chosen, and chosen over other possible sources, the treatment of the יא
suffixes) improves also the scores for the Kasher data. So it is of
interest to note that if the Ginsburger data is removed from the three
Kasher columns in table 14, the
permutation scores drop to 586,547, 127,056, and 214,454 of 106,
respectively.
For the amusement of our readers and to help them appreciate the wealth
of data in Kasher's book that WRR ignored, we include one page out of
Kasher's book as figure 1. (The PostScript
version of this figure is available separately from the main PostScript
file, at http://cs.anu.edu.au/~bdm/dilugim/Nations/KasherPage.ps).
For some of these nations, the identification is certain. Thus Yavan
(ןוי) is clearly Ionia, and Madai (ידמ) is clearly
Media since these names have survived unchanged down to our time. Some
identifications are almost universally agreed upon, such as Gomer
(רמג) being identified with the the Cimmerians (Kimmeroi) in the classical authors and Gimirrai in the
cuneiform texts. Some suggestions are intriguing - for example
Westerman's observation ([We]) that Japeth (תפי)
(the name of one of the sons of Noah) agrees phonetically with the
Greek Iapetos, one of the Titans in Greek
mythology, the son of Ouranos and Gaia. Some of the identifications of
the nations are in dispute, and some nations are completely
unidentified.
The organizing principle of the list is also a matter of scholarly
discussion. For example, [AARS, Kr, WF] suggest that the division is geographical: three
spheres of peoples and lands which meet in the region of the Holy Land.
Other organizing principles - by way of life, or by profession, for
example - have been suggested. Some of the names seem to be place
names, some names of tribes or peoples, and some names of individuals.
Suppose a (partial) list of identifications has been worked out in
a given period and in a given language. In the course of time, this
list of identifications will inevitably be corrupted, especially if the
copyist does not speak the language and is completely unfamiliar with the
geographical terms. For example, the printed version of the Babylonian
Talmud (Yoma 10a) identifies Madai and Yavan as "Macedonia and 'as
its name implies'". This is clearly a mistake. Yavan should have been
identified as Macedonia, and the name Madai=Media is unchanged. Obviously
the copyist or the typesetter, not understanding what he was dealing
with, simply transposed the two identifications. (This particular
error was caught by Rabbi Joel Sirkes, see Hagahot haBah ad locum.) In
other places, where we do not know the correct identification of either
the Hebrew original or the Aramaic translation, undetected errors are
unavoidable. This is why the WRR experiment using names from the Targum
Yonatan was meaningless from the start, even without the gaffe of using
Ginsburger's incorrect version.
If reverse occurrences of the word w are not considered in the
computation of c(w,w'), in most cases this does not change the
value of c(w,w') by much, because most names in column 1 of
table 1 simply do not appear in the reversed
text anywhere. But it is still amusing to note that the honest
"relation to the text" result is 25/107 (computed using our
own programs), about 150 times weaker than "the relation to the text
and the reversed text" result computed by WRR.
At this point, when textual matters are at the height of our
concerns, we are lead to consider the textual residues of the ancient
nations, their books and their letters, and the semantic information we
can gather out of these texts, the language, script, and orthography of
these nations. Thus we are led to consider the prefixes רפס (book
of), בתכמ (letter of), תפש (language of), בתכ
(script of), and ביתכ (orthography of). True to the current
context, we test only the relation to the true text and not
the relation to the reversed text. Doing so, we get a
permutation rank of 19/1,000,000 for WGP. For Genesis, the permutation rank is
338/1,000,000, consistent with the fact that two of the prefixes we use
here are taken from the WRR sample.
Note that we have found a reasonable experiment that gets quite
a good result in two different texts simultaneously. The reader may
choose to infer that achieving a good result in only one text is not
much of a challenge.
Could it be that the WGP success is at least partially due to codes
that lie entirely within chapter 10 of Genesis and have nothing to do
with War and Peace? This would be the case, and it would weaken our point
considerably, if it turns out that there are many ELSs for expressions of
the form pX entirely within chapter 10 of Genesis, where p
is one of the 5 prefixes listed above and X is one of the 68
descendents of Noah. But it turns out that the number of such ELSs in
chapter 10 of Genesis is precisely zero.
Some of the nations in [Genesis,
chapter 10] appear there with some grammatical prefixes and/or
suffixes, and not in the raw form. Namely, nations 36-44 (from
יסוביה through יתמחה) appear with both the definite
article prefix ה and the possessive suffix י, and
nations 13, 14 and 26-33 (םיתכ, םינדד, and from
םידול to םירתפכ) appear with the plural suffix
םי. It makes sense to experiment with the raw nation names
(without the prefixes and suffixes). Here are some results:
Comments:
In table 15 we find the only
examples of modifications of the WRR experiment that improve its
results. In view of the large number of modifications we examined, all
that these exceptions indicate is that WRR did not "play" with these
particular parameters (remember also that "playing" would have required
more computer power than they had, by their own testimony).
The text WGP that we used for some of our examples was the second (of the
two) that we considered (for that purpose). Before switching to WGP we
played briefly with the same verse permuted version of Genesis that WRR
used as a control text. But very quickly we realized that the fact that the
text locations of the 68 names of nations in the permuted Genesis are
evenly spread changes its statistical properties in a significant way and
makes it a very poor control (see a further discussion in section 7).
But as we have seen in section 2, this is
not all. WRR managed to "guess" 3 of the most successful prefixes
without being distracted by some much more "tempting" guesses such as
ינב or ךלמ, which are used in the Bible hundreds of
times, without being distracted by other sources who wrote on chapter
10 of Genesis, without being distracted by other writings of the Vilna
Gaon on that same chapter, and without letting the precise language
used in [VG1] interfere. And as shown in
section 4, almost every other aspect of their
experiment is perfect or near perfect. Is this believable?
Reuven tosses a coin 20 times in a row, and 20 times in a row he claims
that he guessed right which way it will fall, before it actually fell.
Reuven clearly proved something to a significance level of 2-20.
What did Reuven prove?
Finally, we know from section 3 and
section 4.3.1 and from the experience we gained
in [BM] that deliberate cheating can produce
results that appear to be highly significant without really being so.
Much as I thank David for introducing me to this subject, and much
as I learned from (but not enjoyed!) working on it, it is time for me
to move on (and back) to other things, or else the harm already done to
my career will grow fatal and my kids will go hungry. So except for
some commitments I have already made (the most important of which is
moral support to Brendan), I quit from this subject. This paper is sure
to get a response from WRR, and I (and my co-authors) may get
personally attacked. My future lack of response should not be
interpreted as my inability to respond, but rather as my concern
for my family.
I first approached the results of WRR with a great deal of
scientific (and personal) curiosity. The results of [WRR1],
and even more so, of [WRR2, WRR3], seemed very solid,
and, if true, they would have been one of the most significant human
discoveries ever. As the findings reported here have unfolded, my
curiosity turned into anger, and over the 5-6 months that we spent
writing this paper, my anger got replaced by fond memories of the good
old times before all of that, when I was studying honest mathematics.
It is a good time to quit.
The basic problem should be clear to anyone who studies
table 1. The Nations Sample is about the
c(w,w')-distance between the words in the column labeled X and
the words in the other columns. But there is an obvious structural
correlation between these two sets of words; most of the words
w' in columns 2-8 are just extensions of the corresponding
words in the first column. Therefore their lengths are correlated and
their letter-contents are correlated. Thus there is a clear structural
difference between the identity permutation and any other permutation;
anybody (even a computer) can pick out the identity permutation from
within a billion random permutation by looking at completely
structural properties of the lists, completely independently of
the text, without the need of any understanding of the historical
or theological context.
It is the job of the distance function c(w,w') and the
statistical analysis to filter out this effect. They should have been
designed in such a way that the obvious structural peculiarity of the
identity permutation would not give it any a-priori advantage (or
disadvantage) over a randomly chosen permutation. Unfortunately,
c(w,w') and P2 do not do their job properly,
and the identity permutation remains distinguished. This undermines the
permutation test and renders its results invalid.
In section 7.1 we show the results of some very
brief tests we did on control texts. A distinct non-uniformity in the
permutation ranks is noted, especially at the extremes. However,
Genesis does not seem at all exceptional from this point of view.
In section 7.2 we offer some preliminary discussion.
Several things can be seen from the table. There does seem to
be an excessive number of ranks in the smallest bin, and the minimums
appear to be smaller than expected.
(For 136
independent uniform variables, the expected minimum is 7299.)
One might imagine in that evidence of codes, but that would be
unfounded. A minimum of 500 or less is not very unlikely (almost 6.6%
if the ranks are uniform and independent). Moreover, the minima for
Genesis and WGP are about the same, and the tiny differences between
the "original" and "restricted" distributions show that to be not
primarily due to the Genesis 10 portion of WGP.
Standard goodness-of-fit tests fail to show any difference between
the distributions for Genesis and WGP, even though they do verify
that the overall non-uniformity is probably real.
To investigate whether non-uniformity and exaggerated extremes
are the norm, we ran the same tests on 10 control texts.
We generated each control text by randomly permuting the order of the
words within each verse of Genesis except for the verses in Chapter 10.
Chapter 10, where all nation names are found in a specific fixed order,
was left alone in order to make the comparison with Genesis and WGP
more meaningful.
The results are tabulated below. ELSs within Chapter 10 are
ignored, just as for the "restricted" columns in the previous table.
(However, as for the previous table, this restriction
makes hardly any difference.)
The most obvious characteristic of these distributions is their
inconsistency. A few are near-uniform, but others are skewed markedly
in the positive or negative direction. Both the minima and maxima
appear exaggerated.
Several things should be clear from these results. Firstly, WRR's
assumption of uniformity in the rank orders is unfounded, as many of
the texts give profoundly non-uniform distributions. More importantly,
the non-uniformity may be more pronounced at the extremes of the
distribution where WRR measure their "significance levels".
Given the absence of any real evidence of a non-chance phenomenon,
it is hard to see much justification for the months-long study that
would be needed to understand the permutation test properly in this context.
However, we can make a few pertinent observations.
Take the artificial example of two nation names, ABCD and EFGH,
and two prefixes, WX and YZ.
If EFGH has many ELSs (compared to perturbed ELSs) with a letter
close to an appearance of ABCD in the text, then both
c(ABCD,WXEFGH) and c(ABCD,YZEFGH) have an
enhanced probability of being small. Similarly for the opposite
extreme. Thus, c(ABCD,WXEFGH) and c(ABCD,YZEFGH)
will tend to be positively correllated.
This applies to each pair of prefixes, but the degree of correllation
will depend in a complicated manner on the lengths of the prefixes and
the letters they contain.
This correllation between the prefixes could partly explain the
overall non-uniformity evident in the tables above. It also undermines
the WRR result severely, as they use four prefixes at once and they
will tend to reinforce each other. However, it is not clear whether
the correllation adequately explains the actual shape of the
distribution or the exaggerated extremes.
Another contribution to the confusion is the natural clumpiness
of letter distributions through the text. If w and
w' have letters in common, this clumpiness will tend
to make c(w,w') smaller than expected. Obviously, this
favors the identity permutation especially.
Other factors are operating as well, but we don't pretend to
know their effect. Our lack of understanding is illustrated by the
absence of any plausible theory to explain the exaggerated maximum
scores in our experiments. However, we are not embarrassed by this
situation. The embarrassment belongs to WRR, who used their
defective methods without even acknowledging that there were
questions to be asked about them.
A final point to make is that even if Genesis gave profoundly
different results from randomly-generated control texts,
we would not know the reason. Anyone with a small amount of
Hebrew can see at a glance that Genesis is not random, so why
should we expect it behave as if it is? Natural texts have many
statistical properties that random texts don't, including
clumpiness of letter distributions at all scales, short-range
correllations, and perhaps [ASEAS] long-range correllations.
How do we know that WRR's ELS experiment is not just measuring some
property of natural texts? (Recall that in WRR's experiment the identity
permutation is structurally distinct!) The question suggests using other
natural texts as controls, but why should we expect those to behave
quantitatively like Genesis? The lack of suitable controls for
computer analysis of biblical texts is a well known dilemma.
See [Bar] for a discussion.
WRR - Modified Ginsburger
Kasher
Modified Kasher
Modified Kasher, reducing וו
#
38
138
128
127
Score:
4,277
251,140
9,615
27,120
4.2.4. More on Genesis, chapter 10
Chapter 10 of Genesis, known as the Table of Nations, is a unique document
in all of ancient literature. Much effort throughout history has been
devoted to identifying the nations named in the table. For a partial
survey of the literature up to 1971, see the bibliographical references
at the beginning of [We, Chapter 10]. A
computer search has yielded many many more references. It is certainly
not our intent to give a survey of this vast field, nor are we competent
to do so. But a few remarks are in order.
4.3. Other nice experiments
4.3.1. The relation to the text
The title of [WRR2] contains the phrase "the relation to the
text". But instead of measuring the relation to the text, their
distance function c(w,w') measures the relation to the text
and to the reversed text - in the computation of c(w,w') the
word w is searched for with both skip +1 (text) and skip -1
(reversed text). This means, for example, that in the computation of
c(שמ, שמ ץרא), not only occurrences of the word
שמ in the text of Genesis are considered, but also all 519
occurrences of the word םש, whose meaning is completely different.
Thus the phrase "the relation to the text" is false advertising, and should
have been replaced by "the relation to the text and the reversed text".
4.3.2. The identifications of the nations and countries
Column 2 of table 1 contains phrases of the
form Xםע, "the nation of X", and column 7 of that table contains
the "modern" identifications (at least according to WRR) of these nations.
Pretending to believe WRR, we expect that ELS occurrences of the
phrases in column 2 should appear close to ELS occurrences of the words
in column 7. As most phrases in column 2 do not appear in the text or
the reversed text, the appropriate distance function to use here is the
one used in [WRR1]. The permutation rank one gets is 39/100
(on 7 measured distances) - completely insignificant. Similarly it
makes sense to compute the permutation rank of column 2, Xםע,
against column 6, םיX, using the distance function of
[WRR1]. The result is 78/100 (on 20 measured distances).
Finally, column 3, Xץרא against the identifications of the
countries in column 8, gives 16/100 (on 5 measured distances).
4.3.3. An alternate form for "the language of X"
In Hebrew, just as the construct םיX refers to "the people of
X", so does the construct תיX refer to "the language of X" (for
example, when in [WRR3] WRR refer to the language in which
Targum Yonatan is written, they call it "תימרא").
This calls for another experiment - run column 1 of
table 1 against a variant of column 6 in
which all םי suffixes get replaced by תי. The result is
68/100 - a failure.
4.4. Some global choices
This section is different in nature from the previous ones (and from
the following ones) in that it is the only one in which we report on
permutation ranks that are meaningful only if evaluated using at least
a billion permutations, a number so large that according to WRR (in
[WRR3]) it was at the edge of what their computers could
do. (Specifically, they write in a comment following table 6 of
[WRR3] that they couldn't compute the P1
permutation rank (see [WRR1]) with a billion permutations
because they lacked computer power). Thus, in all likelihood, WRR
could not have performed the experiments reported below.
WRR
Deleting ה and י for #36-44
Deleting םי for #13, 14, 26-33
Deleting all grammatical prefixes/suffixes
Ignoring repetitions
(see below) P1 permutation rank
146
17,710
28 (137)
3,420 (12,030)
46
6
5. How much more have we done?
5.1. Disclaimer
We made every effort to ensure that this article is free of substantial
errors. But no scientific piece of work of comparable size can be
entirely error-free. If you find any errors in this article, please let
us know and we will fix them in the next edition (and add your name to
the acknowledgements...).
6. Conclusions
6.1. A Personal note by the first author
I wish to express special thanks to Prof. David Kazhdan of Harvard
University for his insistence (in public and in person) that the WRR
claims on codes in the Book of Genesis deserve serious study, whatever
the conclusions may be.
7. Appendix: Notes on the Metric
7.1. The permutation test on control texts
We begin by summarising the behaviour of the permutation text for
Genesis and WGP, applied for our 136
prefixes. The raw data for some of this table appears in
table 2.
Genesis WGP
bin original restricted forward
original restricted forward 0 21 23 17
23 25 28 1 19 17 21
11 10 12 2 12 9 14
17 13 10 3 12 13 17
12 14 10 4 10 11 6
14 12 12 5 9 12 9
11 15 7 6 11 10 14
5 5 14 7 16 14 17
11 10 8 8 14 16 7
15 14 13 9 12 11 14
17 18 22 min 536 493 1465
527 475 3429 mean 463298 463125 457162
473084 477535 481131 max 990821 990921 996492
997088 998727 997716
bin Text 0 Text 1 Text 2
Text 3 Text 4 Text 5 Text 6
Text 7 Text 8 Text 9 0 15 19 22 23 18
17 14 13 19 19 1 13 13 8 15 12
6 13 18 13 18 2 17 13 16 15 8
18 13 15 11 13 3 13 14 7 9 7
16 18 10 12 11 4 9 7 13 7 10
12 9 13 7 7 5 16 11 13 12 16
5 12 8 10 8 6 10 7 9 22 22
10 8 13 18 10 7 9 13 20 10 9
13 11 15 16 10 8 13 15 15 14 14
23 15 13 11 13 9 21 24 13 9 20
16 22 18 19 27 min 5314 3991
1584 608 874
4979 180 6184
6247 2481 mean 504905 517197
496493 458654 534142
519963 522828 505910
512851 514246 max 999807 999923
999141 997583 999864
999849 999229 997025
991129 998778 7.2. Discussion
8. Bibliography